XML Import in ActiveAdmin (Part 2)
… or a journey to the wonderful world of regular expressions.
In Part 1 I showed you how to build a simple XML import form in ActiveAdmin. But what if our app isn’t quite that simple as I described there. It may look something like this:
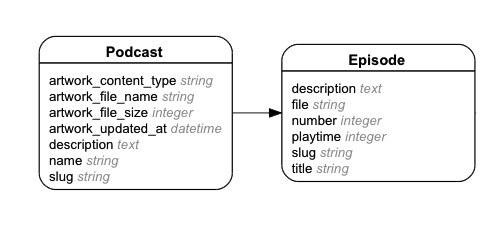
Since we have multiple podcasts I need a podcast model with name, description and artwork. The artwork columns were generated by Paperclip and the slug is used by FriendlyId. The episode model is pretty self-explanatory, I think.
Parse Podcast, Episode # and Title
The XML I got from Wordpress looks something like this:
<channel>
<!-- Some stuff -->
<item>
<title>Celluloid 018: Guy Ritchie</title>
<link>http://www.talesofinterest.de/celluloid-018-guy-ritchie/</link>
<pubDate>Fri, 19 Oct 2012 07:48:18 +0000</pubDate>
<dc:creator>code-chimp</dc:creator>
<guid isPermaLink="false">http://www.talesofinterest.de/?p=745</guid>
<description></description>
<content:encoded>A bunch of Important stuff</content:encoded>
<!-- Some meta stuff -->
</item>
<!-- Some more items -->
</channel>
We need to figure out how to get the podcast name, episode number and episode title out of this. The easy way would be, of course, if we had tagged the posts of each podcast with each own category. Unfortunately we didn’t do that. But fortunately we titled our posts all following the same formula: podcast_name episode_nr: episode_title.
So we can take the title and scan it with regular expressions1 for our three components:
For our podcast name we scan for any amount of characters which have a whitespace and three digits behind them.
str = "Celluloid 018: Guy Ritchie"
=> "Celluloid 018: Guy Ritchie"
str.scan %r{
( # start capture
.+ # one or more of any single character
) # end caputure
\s\d # followed by a whitespace and a digit
}x
=> [["Celluloid"]]
In short that would be:
str.scan(/(.+) \d+/)
=> [["Celluloid"]]
And since scan returns an array and capture wraps another array around the matches, we have to specify which element of the array we want to get the string:
str.scan(/(.+) \d+/)[0][0]
=> "Celluloid"
For the episode number we only have to scan for the first match of three digits followed by a colon and turn the match into an integer.
str.scan(/(\d+):/)[0][0].to_i
=> 18
And for the episode title we scan for everything after a colon and a whitespace:
str.scan(/:\s(.+)/)[0][0]
=> "Guy Ritchie"
Including this into our import_xml action, it now looks like this:2
collection_action :import_xml, method: :post do
items = Nokogiri::XML(params[:import][:file]).xpath("//channel//item")
items.each do |item|
podcast_name = item.at_xpath("title").text.scan(/(.+) \d+/)[0][0]
podcast = Podcast.find_by_name(name) || Podcast.create!(name: name)
Episode.create!(podcast: podcast,
number: item.at_xpath("title").text.scan(/\d+/)[0].to_i,
title: item.at_xpath("title").text.scan(/:\D(.+)/)[0][0],
description: item.at_xpath("content:encoded").text,
created_at: item.at_xpath("pubDate").text)
end
redirect_to admin_podcasts_path, notice: "Episodes imported successfully!"
end
Converting the Episode Description to Markdown
Like in this blog, I’m doing all the writing on the podcast page in Markdown and while most Markdown parser will let HTML pass through, I’d rather have all my podcast descriptions in the same format. I’ve tried a few gems that do HTML to Markdown conversion and none of them were perfect for this use-case.3 The one getting closest was html2markdown, to which I made a few changes until I was satisfied. Let’s add the gem to our Gemfile:
gem 'html2markdown', git: 'git@github.com:coding-chimp/html2markdown.git'
Run the bundle install command and use it in the import method:
collection_action :import_xml, method: :post do
items = Nokogiri::XML(params[:import][:file]).xpath("//channel//item")
items.each do |item|
podcast_name = item.at_xpath("title").text.scan(/(.+) \d+/)[0][0]
podcast = Podcast.find_by_name(name) || Podcast.create!(name: name)
description = HTMLPage.new :contents => item.at_xpath("content:encoded").text
description = description.markdown
Episode.create!(podcast: podcast,
number: item.at_xpath("title").text.scan(/\d+/)[0].to_i,
title: item.at_xpath("title").text.scan(/:\D(.+)/)[0][0],
description: description,
created_at: item.at_xpath("pubDate").text)
end
redirect_to admin_podcasts_path, notice: "Episodes imported successfully!"
end
That’s it. Pretty easy, wasn’t it?
Rubular is a very cool site on which you can test your regular expressions. ↩︎
Due to the structure of my app, the form actually is in my podcasts index and not the episodes index as said in the last post. That doesn’t change the code, though. ↩︎
It’s probably just because we’re not working with clean HTML here. ↩︎